

Speeding up the JavaScript ecosystem - Semver

tl;dr: During the installation process, package managers run a bunch of semver comparisons. The semver library used in npm, yarn and pnpm can be made around 33x faster.
- Part 1: PostCSS, SVGO and many more
- Part 2: Module resolution
- Part 3: Linting with eslint
- Part 4: npm scripts
- Part 5: draft-js emoji plugin
- Part 6: Polyfills gone rogue
- Part 7: The barrel file debacle
- Part 8: Tailwind CSS
- Part 9: Server Side JSX
- Part 10: Isolated Declarations
- Part 11: Rust and JavaScript Plugins
- Part 12: Semver
Whilst dabbling with the Preact repo I noticed that running npm install takes more than 3s. This seems excessively long and piqued my interest. I was waiting for a good use case to try out cpupro anyway, so this seemed like a perfect fit.
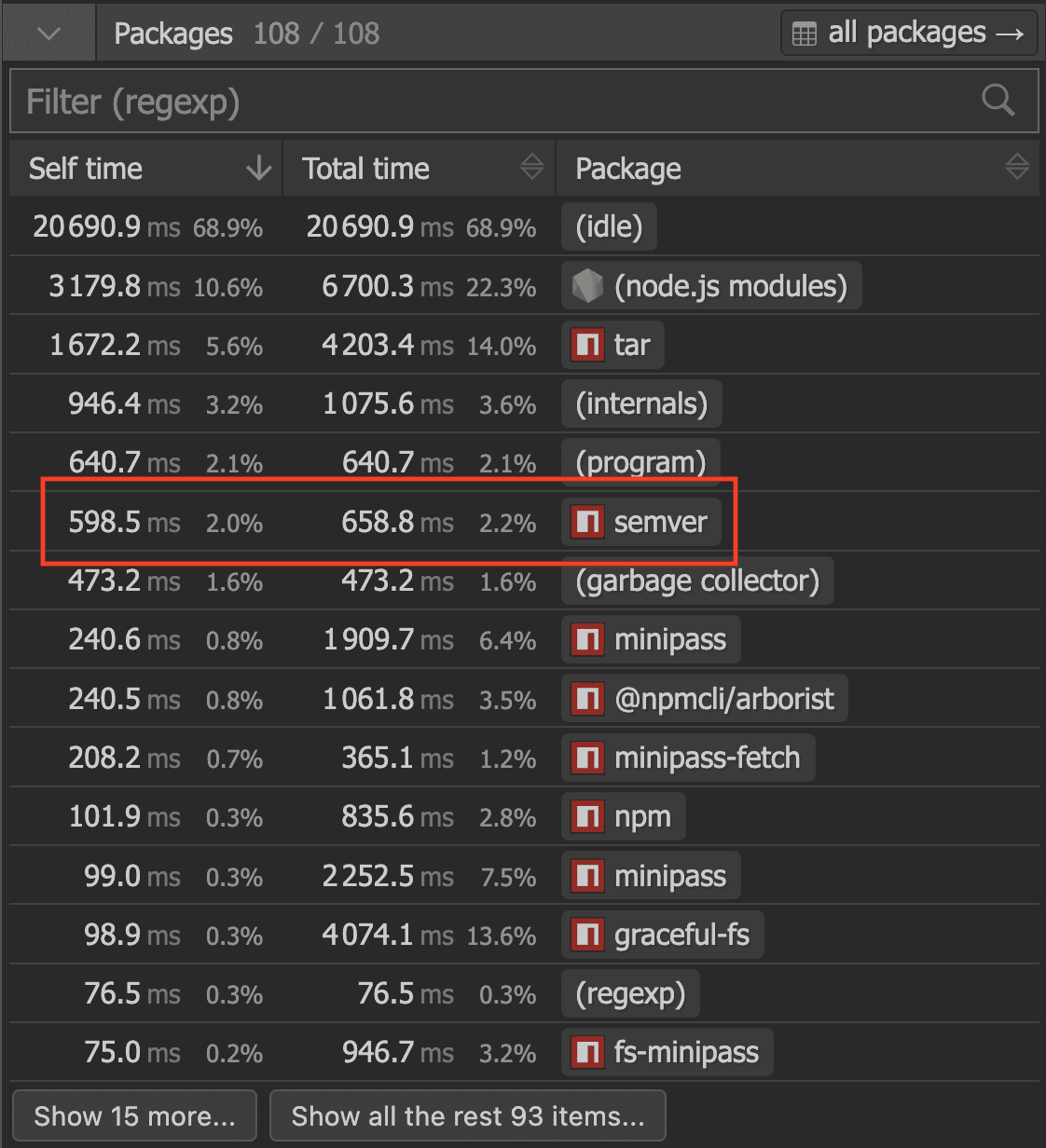
The tar library is kinda expected to be up there as a decent amount of time is spent extracting tarballs. What captured my attention was the semver package though. It's the package that compares all version ranges of all the dependencies in your project to figure out which versions to install. The versioning is based on the semver standard which defines a major, minor, patch and an optional prerelease component:
1.2.3 # major.minor.patch
2.0.0-alpha.3 # major.minor.patch-prereleasePackage managers go beyond that to allow you to specify ranges or constraints. Instead of only allowing exact versions, they allow you to pass something like ^1.0.0 which means: "Allow any minor or patch version bigger than this version. Ranges can also be composed. You'll often find this sort of format when declaring peerDepdendencies: 1.x || 2.x. Npm supports a plethora of ways to express desired version ranges for your dependencies.
1.2.3 # =1.2.3
4.0.0-alpha.4 # =4.0.0-alpha.4
4.0.0-2 # =4.0.0-2
# Partial versions are also possible
1 # =1.0.0
1.2 # =1.2.0
# Ranges
^2.0.0 # >= 2.0.0 && <3.0.0
~2.0.0 # >= 2.0.0 && <2.1.0
1.x || 2.x # >=1.0.0 || >=2.0.0
1.2.3 - 1.4.0 # >=1.2.3 && <=1.4.0
1.x # >=1.0.0
# ...and moreParse, don't validate
To get some idea how often the npm binary calls into semver, I've cloned the npm repository, ran npm install and wrapped all exports of the semver library with functions that log out which function was called and with what arguments.
Doing an installation in the preact repo calls about 21.2k times in total into the semver. That's way more than I would've expected. Here are some stats of the functions called:
| Function | Callcount |
|---|---|
| `satisfies` | 11151 |
| `valid` | 4878 |
| `validRange` | 4911 |
| `sort` | 156 |
| `rcompare` | 79 |
| `simplifyRange` | 24 |
Looking at the table we can see that the call count is entirely dominated by validating and checking if version constraints are satisfied. And that makes sense, because that's what a package manager is supposed to do during installation of dependencies. Looking at the raw function call logs we can see a common pattern:
valid [ '^6.0.0', true ]
validRange [ '^6.0.0', true ]
satisfies [ '6.0.0', '^6.0.0', true ]
valid [ '^0.5.0', true ]
validRange [ '^0.5.0', true ]
satisfies [ '0.5.0', '^0.5.0', true ]
valid [ '^7.26.0', true ]
validRange [ '^7.26.0', true ]
satisfies [ '7.26.0', '^7.26.0', true ]
valid [ '^7.25.9', true ]
validRange [ '^7.25.9', true ]
satisfies [ '7.25.9', '^7.25.9', true ]
valid [ '^7.25.9', true ]
validRange [ '^7.25.9', true ]
satisfies [ '7.25.9', '^7.25.9', true ]
valid [ '^7.26.0', true ]
validRange [ '^7.26.0', true ]
satisfies [ '7.26.0', '^7.26.0', true ]A huge portion of the satisfies calls are preceded by a call to both valid and validRange. This hints at us that these two functions are used to validate the arguments passed to satisfies. Since the source of the npm cli is public we can check the source code for what these functions are doing.
const valid = (version, options) => {
const v = parse(version, options);
return v ? v.version : null;
};
const validRange = (range, options) => {
try {
// Return '*' instead of '' so that truthiness works.
// This will throw if it's invalid anyway
return new Range(range, options).range || "*";
} catch (er) {
return null;
}
};
const satisfies = (version, range, options) => {
try {
range = new Range(range, options);
} catch (er) {
return false;
}
return range.test(version);
};To validate input correctness, both validator functions parse the input data, allocate the resulting data structure and return back the original input string if it passed the check. When we call the satisfies function, we do the same work that we just threw away again. This is a classic case of doing twice the work necessary due to not following the "Parse, don't validate" rule.
Everytime you're dealing with parsers and you're validating the inputs before doing the parsing you're burning unnecessary CPU cycles. Parsing itself is a form of validation. It's pointless. By getting rid of the duplicate validation we can save about 9.8k function calls.
With us having logged the function calls prior, we have an ideal benchmark case and can measure the timings with and without duplicate validation. For that I'm using the deno bench tool.
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| validate + parse | 99.9 ms | 10.0 | ( 85.5 ms … 177.3 ms) | 91.1 ms | 177.3 ms | 177.3 ms |
| parse | 28.0 ms | 35.7 | ( 22.8 ms … 73.3 ms) | 26.4 ms | 73.3 ms | 73.3 ms |
Removing the duplicate validation gives us a nice speedboost already. It makes the code ~70% faster.
Does slapping a cache in front of things help?
Over time the folks working on the semver library realized this problem and added an LRU cache, which is sorta a special variant of a Map in JavaScript terms that has a limited number of entries. This is done to avoid the Map growing indefinitely in size. And it turns out it's somewhat effective at speeding things up. Logging out whether a cache entry was found or missed reveals that only 523 times out of 26k calls returned a non-cached result. That's pretty good!
If we remove the caching we can get an idea of how much time it saved.
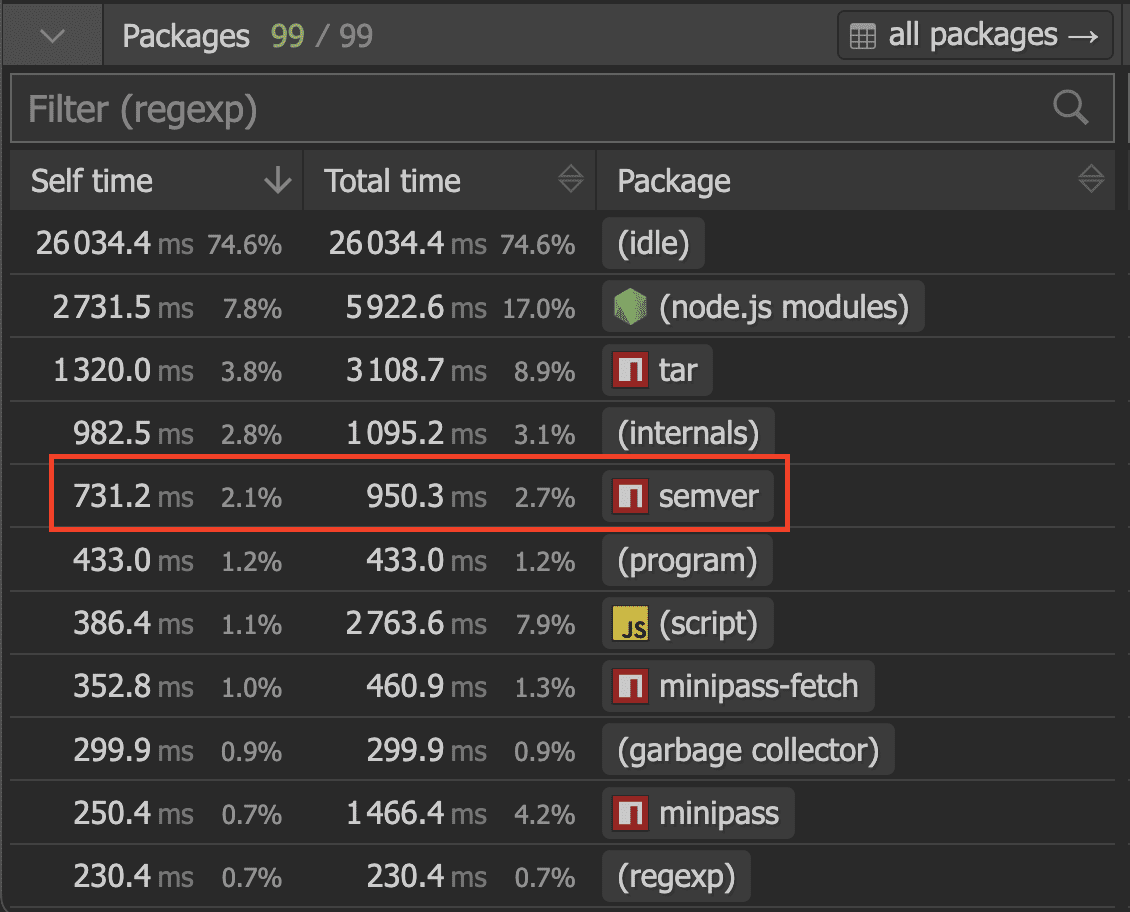
In total, adding the cache saved about 133ms. Which I guess is not nothing, but far from being effective in the grand picture, despite the amount of cache hits.
| Scenario | Time |
|---|---|
| Uncached | `731ms` |
| Cached | `598ms` |
Caches are a bit of a pet peeve of mine. They can be incredibly useful if used sparingly at the right places, but they are notoriously overused across the JavaScript ecosystem. It often feels like a lazy way to increase performance, where instead of making your code fast, you try to cache the results and kinda hope for the best. Making your code fast instead, yields much better results in many cases.
Caches should be seen as the last form of measure to take when all other options have been exhausted.
How fast can we make it?
With semver having a small grammar to parse, I kinda felt nerdsniped to have a go at it myself. Over the course of a day I wrote a semver parser and added support for all the ways npm allows you to specify a semver constraint. The code is doing nothing out of the ordinary. It loops over the input string, detects the relevant tokens and creates the final data structures out of that. Anyone familiar with parsers would've come up with the same code. It's doing nothing special. No secret JavaScript performance tricks or anything.
function parseSemver(input: string): Semver {
let ctx = { input, i: 0 };
let major = 0;
let ch = ctx.input.charCodeAt(ctx.i);
if (ch >= Char.n0 || ch <= Char.n9) {
major = parseNumber(ctx);
} else {
throw invalidErr(ctx);
}
ch = expectDot(ctx);
let minor = 0;
if (ch >= Char.n0 || ch <= Char.n9) {
minor = parseNumber(ctx);
} else {
throw invalidErr(ctx);
}
// ...and so on
}And then we need some code that can check if a version satisfies semver constraints, which is structured in a similar way.
With us having logged all function calls prior, we have the ideal dataset for a benchmark. For the first one, although I've kept the validate + parse steps.
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| node-semver | 99.9 ms | 10.0 | ( 85.5 ms … 177.3 ms) | 91.1 ms | 177.3 ms | 177.3 ms |
| custom | 3.9 ms | 255.3 | ( 3.7 ms … 6.1 ms) | 4.0 ms | 4.7 ms | 6.1 ms |
Even with doing the unnecessary validate step, the custom parser is 25x faster. If we capture a CPU profile of the amount of work done, the difference is even more stark.
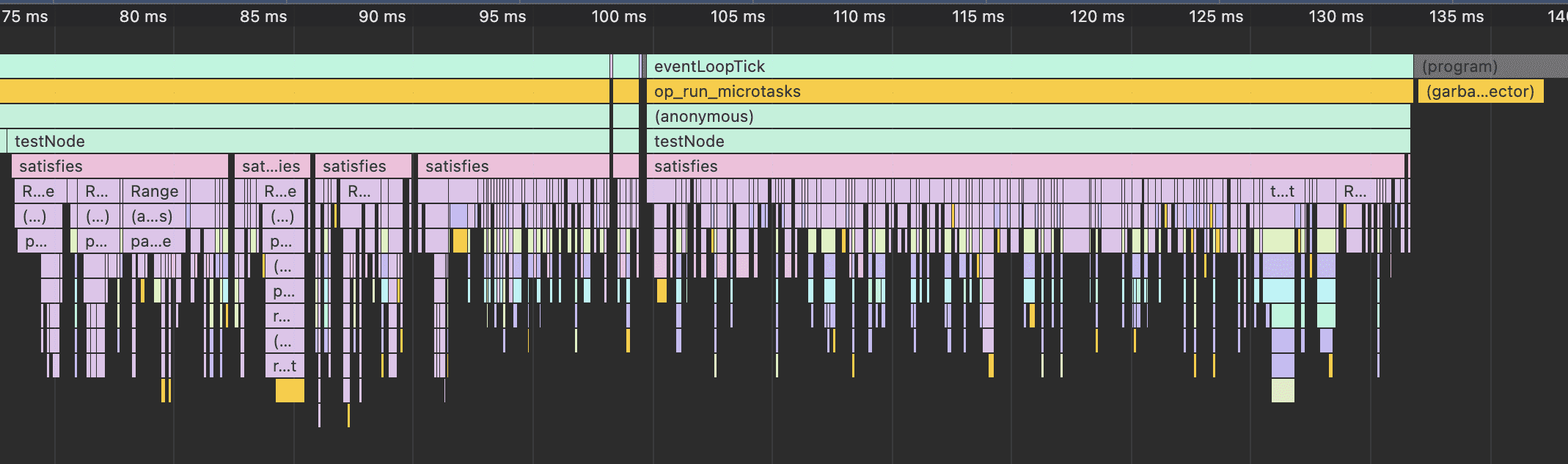
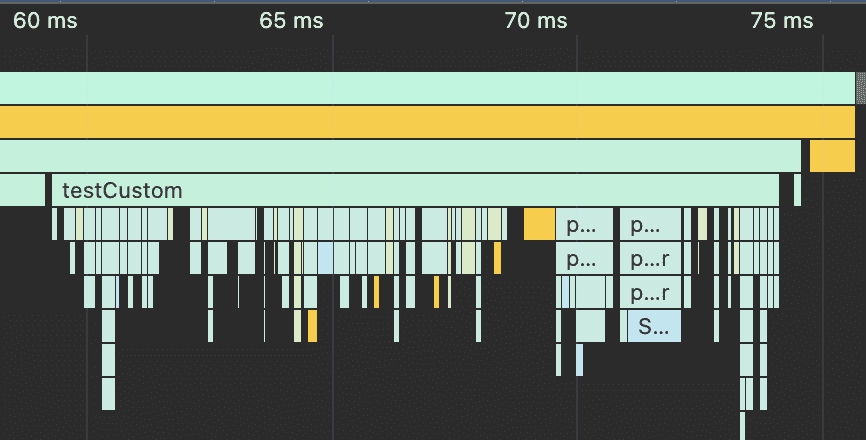
Let's get rid of the unnecessary validation step for the next benchmark for both of them.
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| node-semver | 28.0 ms | 35.7 | ( 22.8 ms … 73.3 ms) | 26.4 ms | 73.3 ms | 73.3 ms |
| custom | 2.9 ms | 347.2 | ( 2.7 ms … 6.4 ms) | 2.9 ms | 3.4 ms | 6.4 ms |
With a level playing field of not doing unnecessary validation the difference is much smaller, but still in the order of 10x faster. So in summary the semver checks can be made 33x faster than they are now.
Conclusion
As usual, the tools in the JavaScript ecosystem aren't slow because of the language, but because of slow code. At the time of this writing, the semver library is used in all popular package managers. It's used in npm, yarn and pnpm. Making this faster or switching to a faster alternative would speed the installation process up considerably for all of them.