

Speeding up the JavaScript ecosystem - module resolution

📖 tl;dr: Whether you’re building, testing and/or linting JavaScript, module resolution is always at the heart of everything. Despite its central place in our tools, not much time has been spent on making that aspect fast. With the changes discussed in this blog post tools can be sped up by as much as 30%.
- Part 1: PostCSS, SVGO and many more
- Part 2: Module resolution
- Part 3: Linting with eslint
- Part 4: npm scripts
- Part 5: draft-js emoji plugin
- Part 6: Polyfills gone rogue
- Part 7: The barrel file debacle
- Part 8: Tailwind CSS
- Part 9: Server Side JSX
- Part 10: Isolated Declarations
- Part 11: Rust and JavaScript Plugins
In part 1 of this series we found a few ways to speed various libraries used in JavaScript tools. Whilst those low level patches moved the total build time number by a good chunk, I was wondering if there is something more fundamental in our tooling that can be improved. Something that has a greater impact on the total time of common JavaScript tasks like bundling, testing and linting.
So over the next couple of days I collected about a dozen CPU profiles from various tasks and tools that are commonly used in our industry. After a bit of inspection, I came across a repeating pattern that was present in every profile I looked at and affected the total runtime of these tasks by as much as 30%. It’s such a critical and influential part of our infrastructure that it deserves to have its own blog post.
That critical piece is called module resolution. And in all the traces I looked at it took more time in total than parsing source code.
The cost of capturing stack traces
It all started when I noticed that the most time consuming aspect in those traces was spent in captureLargerStackTrace an internal node function responsible for attaching stack traces to Error objects. That seemed a bit out of the ordinary, given that both tasks succeeded without showing any signs of errors being thrown.
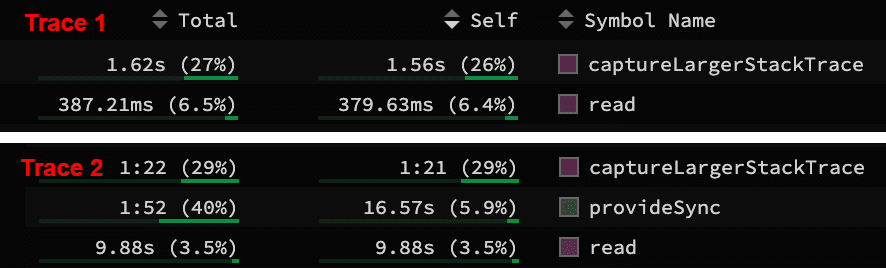
After clicking through a bunch of occurrences in the profiling data a clearer picture emerged as to what was happening. Nearly all of the error creations came from calling node’s native fs.statSync() function and that in turn was called inside a function called isFile. The documentation mentions that fs.statSync() is basically the equivalent to POSIX’s fstat command and commonly used to check if a path exists on disk, is a file or a directory. With that in mind we should only get an error here in the exceptional use case when the file doesn’t exist, we lack permissions to read it or something similar. It was time to take a peek at the source of isFile.
function isFile(file) {
try {
const stat = fs.statSync(file);
return stat.isFile() || stat.isFIFO();
} catch (err) {
if (err.code === "ENOENT" || err.code === "ENOTDIR") {
return false;
}
throw err;
}
}From a quick glance it’s an innocent looking function, but was showing up in traces nonetheless. Noticeably, we ignore certain error cases and return false instead of forwarding the error. Both the ENOENT and ENOTDIR error codes ultimately mean that the path doesn’t exist on disk. Maybe that’s the overhead we’re seeing? I mean we’re immediately ignoring those errors here. To test that theory I logged out all the errors that the try/catch-block caught. Low and behold every single error that was thrown was either a ENOENT code or an ENOTDIR code.
A peek into node’s documentation of fs.statSync reveals that it supports passing a throwIfNoEntry option that prevents errors from being thrown when no file system entry exists. Instead it will return undefined in that case.
function isFile(file) {
const stat = fs.statSync(file, { throwIfNoEntry: false });
return stat !== undefined && (stat.isFile() || stat.isFIFO());
}Applying that option allows us to get rid of the if-statment in the catch block which in turn makes the try/catch redundant and allows us to simplify the function even further.
This single change reduced the time to lint the project by 7%. What’s even more awesome is that tests got a similar speedup from the same change too.
The file system is expensive
With the overhead of stack traces of that function being eliminated, I felt like there was still more to it. You know, throwing a couple of errors shouldn’t really show up at all in traces captured over the span of a couple of minutes. So I injected a simple counter into that function to get an idea how frequently it was called. It became apparent that it was called about 15k times, about 10x more than there were files in the project. That smells like an opportunity for improvement.
To module or not to module, that is the question
By default there are three kind of specifiers for a tool to know about:
- Relative module imports:
./foo,../bar/boof - Absolute module imports:
/foo,/foo/bar/bob - Package imports
foo,@foo/bar
The most interesting of the three from a performance perspective is the last one. Bare import specifiers, the ones that don’t start with a dot . or with a slash /, are a special kind of import that typically refer to npm packages. This algorithm is described in depth in node’s documentation. The gist of it is that it tries to parse the package name and then it will traverse upwards to check if a special node_modules directory is present that contains the module until it reaches the root of the file system. Let’s illustrate that with an example.
Let’s say that we have a file located at /Users/marvinh/my-project/src/features/DetailPage/components/Layout/index.js that tries to import a module foo. The algorithm will then check for the following locations.
/Users/marvinh/my-project/src/features/DetailPage/components/Layout/node_modules/foo//Users/marvinh/my-project/src/features/DetailPage/components/node_modules/foo//Users/marvinh/my-project/src/features/DetailPage/node_modules/foo//Users/marvinh/my-project/src/features/node_modules/foo//Users/marvinh/my-project/src/node_modules/foo//Users/marvinh/my-project/node_modules/foo//Users/marvinh/node_modules/foo//Users/node_modules/foo/
That’s a lot of file system calls. In a nutshell every directory will be checked if it contains a module directory. The amount of checks directly correlates to the number of directories the importing file is in. And the problem is that this happens for every file where foo is imported. Meaning if foo is imported in a file residing somewhere else, we’ll crawl the whole directory tree upwards again until we find a node_modules directory that contains the module. And that’s an aspect where caching the resolved module greatly helps.
But it gets even better! Lots of projects make use of path mapping aliases to save a little bit of typing, so that you can use the same import specifiers everywhere and avoid lots of dots ../../../. This is typically done via TypeScript’s paths compiler option or a resolve alias in a bundler. The problem with that is that these typically are indistinguishable from package imports. If I add a path mapping to the features directory at /Users/marvinh/my-project/src/features/ so that I can use an import declaration like import {...} from “features/DetailPage”, then every tool should know about this.
But what if it doesn’t? Since there is no centralized module resolution package that every JavaScript tool uses, they are multiple competing ones with various levels of features supported. In my case the project makes heavy use of path mappings and it included a linting plugin that wasn’t aware of the path mappings defined in TypeScript’s tsconfig.json. Naturally, it assumed that features/DetailPage was referring to a node module, which led it to do the whole recursive upwards traversal dance in hopes of finding the module. But it never did, so it threw an error.
Caching all the things
Next I enhanced the logging to see how many unique file paths the function was called with and if it always returned the same result. Only about 2.5k calls to isFile had a unique file path and there was a strong 1:1 mapping between the passed file argument and the returned value. It’s still more than the amount of files in the project, but it’s much lower than the total 15k times it was called. What if we added a cache around that to avoid reaching out to the file system?
const cache = new Map();
function resolve(file) {
const cached = cache.get(file);
if (cached !== undefined) return cached;
// ...existing resolution logic here
const resolved = isFile(file);
cache.set(file, resolved);
return file;
}The addition of a cache sped up the total linting time by another 15%. Not bad! The risky bit about caching though is that they might become stale. There is a point in time where they usually have to be invalidated. Just to be on the safe side I ended up picking a more conservative approach that checks if the cached file still exists. This is not an uncommon thing to happen if you think of tooling often being run in watch mode where it’s expected to cache as much as possible and only invalidate the files that changed.
const cache = new Map();
function resolve(file) {
const cached = cache.get(file);
// A bit conservative: Check if the cached file still exists on disk to avoid
// stale caches in watch mode where a file could be moved or be renamed.
if (cached !== undefined && isFile(file)) {
return cached;
}
// ...existing resolution logic here
for (const ext of extensions) {
const filePath = file + ext;
if (isFile(filePath)) {
cache.set(file, filePath);
return filePath;
}
}
throw new Error(`Could not resolve ${file}`);
}I was honestly expecting it to nullify the benefits of adding a cache in the first place since we’re reaching to the file system even in the cached scenario. But looking at the numbers this only worsened the total linting time only by 0.05%. That’s a very minor hit in comparison, but shouldn’t the additional file system call matter more?
The file extension guessing game
The thing with modules in JavaScript is that the language didn’t have a module system from the get go. When node.js came onto the scene it popularized the CommonJS module system. That system has several “cute” features like the ability to omit the extension of the file you’re loading. When you write a statement like require("./foo") it will automatically add the .js extension and try to read the file at ./foo.js. If that isn’t present it will check for json file ./foo.json and if that isn’t available either, it will check for an index file at ./foo/index.js.
Effectively we’re dealing with ambiguity here and the tooling has to make sense of what ./foo should resolve to. With that there is a high chance of doing wasted file system calls as there is no way of knowing where to resolve the file to, in advance. Tools literally have to try each combination until they find a match. This is worsened if we look at the total amount of possible extensions that exist today. Tools typically have an array of potential extensions to check for. If you include TypeScript the full list for a typical frontend project at the time of this writing is:
const extensions = [
".js",
".jsx",
".cjs",
".mjs",
".ts",
".tsx",
".mts",
".cts",
];That’s 8 potential extensions to check for. And that’s not all. You essentially have to double that list to account for index files which could resolve to all those extensions too! This means that our tools have no other option, other than looping through the list of extensions until we find one that exists on disk. When we want to resolve ./foo and the actual file is foo.ts, we’d need to check:
foo.js-> doesn’t existfoo.jsx-> doesn’t existfoo.cjs-> doesn’t existfoo.mjs-> doesn’t existfoo.ts-> bingo!
That’s four unnecessary file system calls. Sure you could change the order of the extensions and put the most common ones in your project at the start of the array. That would increase the chances of the correct extension to be found earlier, but it doesn’t eliminate the problem entirely.
As part of the ES2015 spec a new module system was proposed. All the details weren’t fleshed out in time, but the syntax was. Import statements quickly took over as they have very benefits over CommonJS for tooling. Due to its staticness it opened up the space for lots more tooling enhanced features like most famously tree-shaking where unused modules and or even functions in modules can be easily detected and dropped from the production build. Naturally, everyone jumped on the new import syntax.
There was one problem though: Only the syntax was finalized and not how the actual module loading or resolution should work. To fill that gap, tools re-used the existing semantics from CommonJS. This was good for adoption as porting most code bases only required syntactical changes and these could be automated via codemods. This was a fantastic aspect from an adoption point of view! But that also meant that we inherited the guessing game of which file extension the import specifier should resolve to.
The actual spec for module loading and resolution was finalized years later and it corrected this mistake by making extensions mandatory.
// Invalid ESM, missing extension in import specifier
import { doSomething } from "./foo";
// Valid ESM
import { doSomething } from "./foo.js";By removing this source of ambiguity and always adding an extension, we’re avoiding an entire class of problems. Tools get way faster too. But it will take time until the ecosystem moves forward on that or if at all, since tools have adapted to deal with the ambiguity.
Where to go from here?
Throughout this whole investigation I was a bit surprised to find that much room for improvement in regards to optimizing module resolution, given that it’s such a central in our tools. The few changes described in this article reduced the linting times by 30%!
The few optimizations we did here are not unique to JavaScript either. Those are the same optimizations that can be found in toolings for other programming languages. When it comes to module resolution the four main takeaways are:
- Avoid calling out to the file system as much as possible
- Cache as much as you can to avoid calling out to the file system
- When you're using
fs.statorfs.statSyncalways set thethrowIfNoEntry: false - Limit upwards traversal as much as possible
The slowness in our tooling wasn’t caused by JavaScript the language, but by things just not being optimized at all. The fragmentation of the JavaScript ecosystem doesn't help either as there isn’t a single standard package for module resolution. Instead, there are multiple and they all share a different subset of features. That’s no surprise though as the list of features to support has grown over the years and there is no single library out there that supports them all at the time of this writing. Having a single library that everyone uses would make solving this problem once and for all for everyone a lot easier.