

Speeding up the JavaScript ecosystem - draft-js emoji plugin

tl;dr: A regex was constructed from scratch 7138 times from a 42kB heavy string. Caching that computation greatly speeds up the initialization phase of the draft-js emoji plugin.
- Part 1: PostCSS, SVGO and many more
- Part 2: Module resolution
- Part 3: Linting with eslint
- Part 4: npm scripts
- Part 5: draft-js emoji plugin
- Part 6: Polyfills gone rogue
- Part 7: The barrel file debacle
- Part 8: Tailwind CSS
- Part 9: Server Side JSX
- Part 10: Isolated Declarations
- Part 11: Rust and JavaScript Plugins
- Part 12: Semver
I received a very interesting issue via email from Josh Goldberg regarding a website that froze for about 2-3s. The website uses the draft-js rich text editor for some inputs and he was able to narrow it down to something going wrong in the emoji plugin for draft-js. So we decided to hop on a call and continue debugging together.
Capturing a quick recording via Chrome's profiler confirms the initial suspicions. Something is up with the emoji plugin. We can see a lot of frequent function calls at the bottom that take up the majority of time. Unfortunately, Chrome's profiler doesn't have some sort of "left-heavy" visualization like speedscope does. This makes it a little harder to see which function is worth investigating. The "left-heavy" is nicer for that as it merges similar callstacks into one.
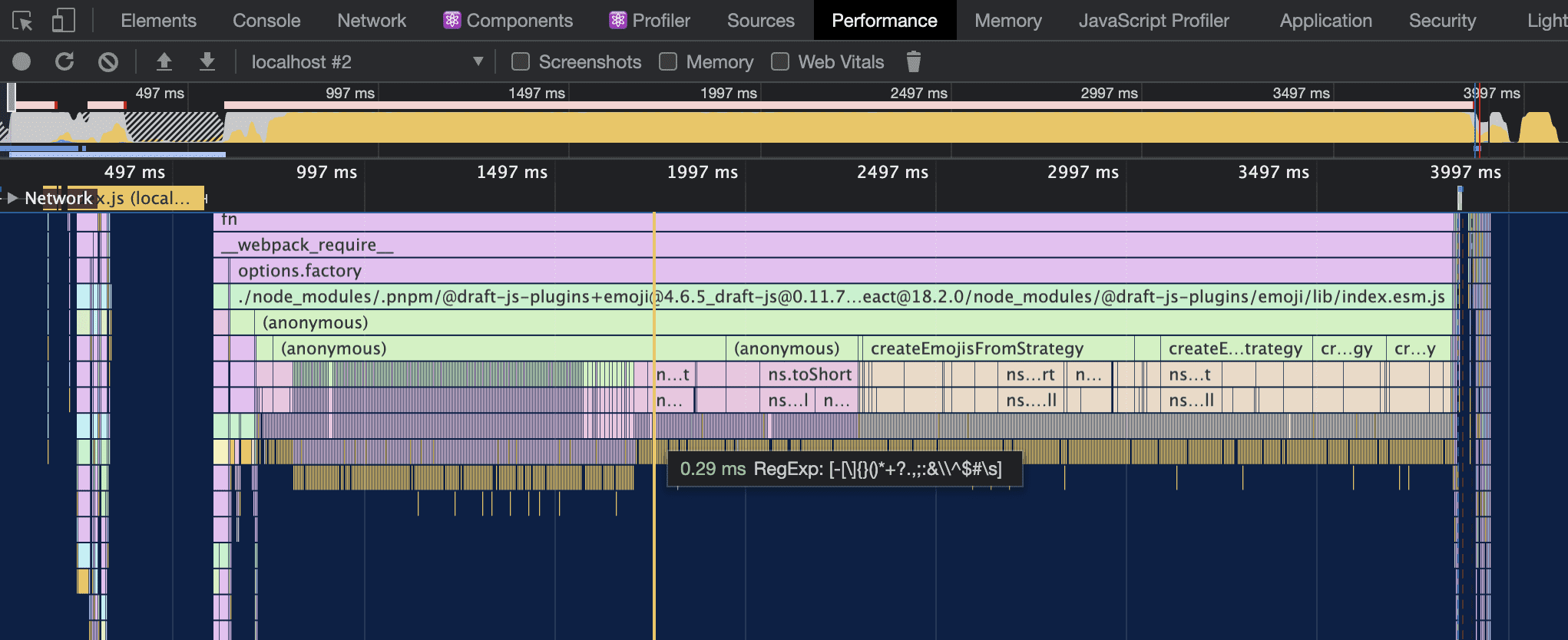
Each individual call seemed fine and always ended up with calling into the regex engine. But the high number of calls were enough of a reason for concern. A cool thing about Chrome's profiler is that it can annotate source code lines with the sampled traces. This gives you an approximate time for how much each line took to execute. It's not 100% accurate due to the amount of transpilation being involved in frontend projects, but it's good enough to derive some early conclusions.
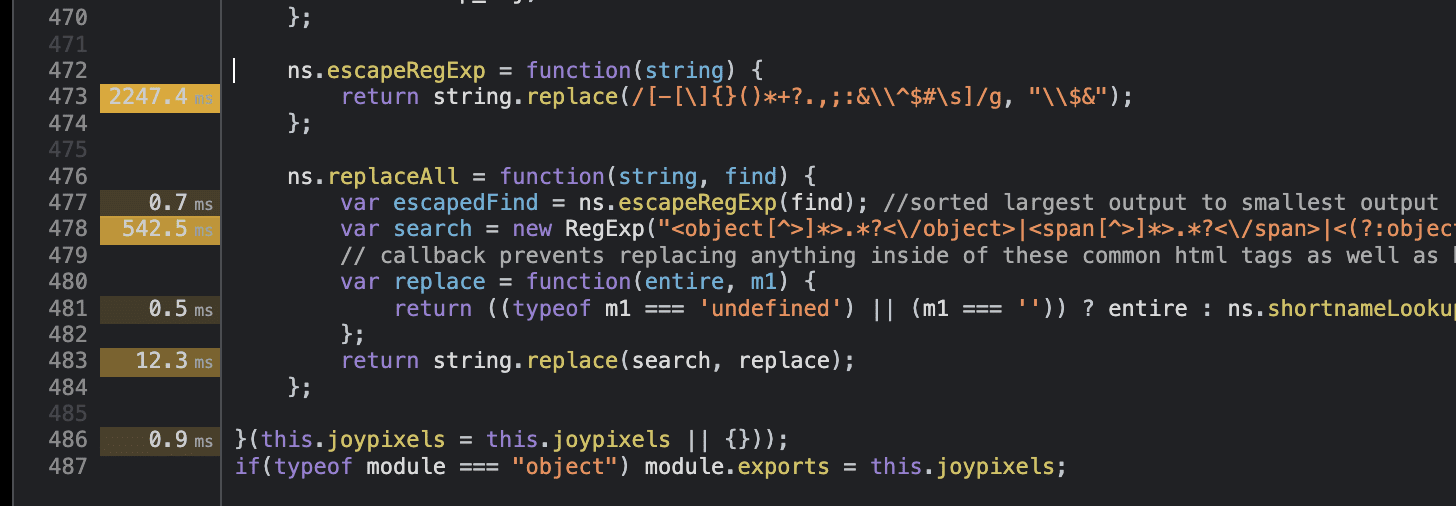
Aha! The two methods that consumed most of the time deal with regexes. It might have been tempting to conclude that the regexes itself were to blame, but I had a feeling that that was merely a symptom of a deeper problem. First thing we checked was how often this function was called. This can be done via incrementing a simple counter or by using console.count() directly.
ns.escapeRegExp = function(string) {
+ console.count("escapeRegExp");
return string.replace(/[-[\]{}()*+?.,;:&\\^$#\s]/g, "\\$&");
};
ns.replaceAll = function(string, find) {
+ console.count("replaceAll");
var escapedFind = ns.escapeRegExp(find);
var search = new RegExp("<object[^>]*>.*?<\/object>|<span[^>]*>.*?<\/span>|<(?:object|embed|svg|img|div|span|p|a)[^>]*>|("+escapedFind+")", "gi");
// ...
};Turns out that the replaceAll method was called 7318 times whenever the page was loaded. Next, we checked what kind of arguments escapeRegExp was called with. The theory being that maybe it's called with the same arguments over and over again.
A minute later that hypothesis proved to be correct as it was escaping the same string over and over again. We know that this method is called from replaceAll, so let's check if we're always passing the same argument there. And sure enough, the first string argument received two different values, but the second find argument was always the same. That's the one that was later passed to escapeRegExp.
The immediate question that popped up was: "Who is calling replaceAll and why are they always passing the same arguments?"

Zooming into the profile again, we observed that all calls to replaceAll had toShort as a common ancestor.

Something very interesting was happening here in that the second argument passed to replaceAll didn't depend on arguments passed to toShort at all. And following the trail of unicodeCharRegex we got a clearer picture of what the purpose of the code here was. Like in popular chat apps like Slack, the plugin for draft-js allows you to type the text :smile: which is then automatically converted to a proper emoji "😀". But the reverse is also needed and that's what we were seeing here.
Finding a solution
Knowing more about the purpose of this code, we noticed that the the regex was built by iterating a big data structure of unicode characters and their metadata. This regex was then applied to the incoming text to match emojis and replace them with the shortcode. With every single call to toShort the regex would be constructed from scratch. It becomes a performance problem, because the unicode standard has a gazillion emojis with variations for skin tones and other things. So yeah, no wonder the resulting regex was huge.

Chrome's console is showing that the generated string from which the regex is constructed is bigger than 42kB alone.
As with most cases of expensive computations, we can avoid a lot of the work by caching the previous result. That way we don't need to recompute the same thing again and again. It's the least invasive fix one can make that doesn't require bigger changes to the architecture of the plugin. We made a PR and it reduced the blocking time from 2-3s down to <200ms in total. That's still a lot more than what we'd like, but that's already night and day in terms of user experience.
We ended our call together at this stage, but it made me wonder what else could be done if we didn't restrict ourselves to keep the current architecture.
Conclusion
If we step back for a second, it seems wasteful to always build up that regex whenever that module is loaded in the first place. The result is always the same, so an optimization would be to store the transformed result and use that from the get go in the plugin instead. That could be built whenever a new version of the plugin is released.
Another potential idea to pursue would be to use a handcrafted function to match emojis. It would allow you to narrow down the search space of potential matches very quickly, but it remains to verify that such an approach would be faster than a regex in this scenario. I think it's worth a shot.
EDIT: Fabio Spampinato shared an even better idea on twitter. Instead of constructing a >40kB regular expressions, we can leverage the recent unicode enhancements. This includes special unicode property escapes like Emoji_Presentation which allows you to match all emojis directly (example: /\p{Emoji_Presentation}/gu). With that we can get rid of all the regex generation code completly. Read more about that on MDN.
Overall this particular issue is a good reminder to profile our code from time to time. It's a reminder that even innocent looking functions can have a huge impact on performance.